| | Chapter 3
Experimental Errors and
Error Analysis This chapter is largely a tutorial on handling experimental errors of measurement. Much of the material has been extensively tested with science undergraduates at a variety of levels at the University of Toronto. Whole books can and have been written on this topic but here we distill the topic down to the essentials. Nonetheless, our experience is that for beginners an iterative approach to this material works best. This means that the users first scan the material in this chapter; then try to use the material on their own experiment; then go over the material again; then ... provides functions to ease the calculations required by propagation of errors, and those functions are introduced in Section 3.3. These error propagation functions are summarized in Section 3.5. 3.1 Introduction 3.1.1 The Purpose of Error Analysis For students who only attend lectures and read textbooks in the sciences, it is easy to get the incorrect impression that the physical sciences are concerned with manipulating precise and perfect numbers. Lectures and textbooks often contain phrases like: For an experimental scientist this specification is incomplete. Does it mean that the acceleration is closer to 9.8 than to 9.9 or 9.7? Does it mean that the acceleration is closer to 9.80000 than to 9.80001 or 9.79999? Often the answer depends on the context. If a carpenter says a length is "just 8 inches" that probably means the length is closer to 8 0/16 in. than to 8 1/16 in. or 7 15/16 in. If a machinist says a length is "just 200 millimeters" that probably means it is closer to 200.00 mm than to 200.05 mm or 199.95 mm. We all know that the acceleration due to gravity varies from place to place on the earth's surface. It also varies with the height above the surface, and gravity meters capable of measuring the variation from the floor to a tabletop are readily available. Further, any physical measure such as can only be determined by means of an experiment, and since a perfect experimental apparatus does not exist, it is impossible even in principle to ever know perfectly. Thus, the specification of given above is useful only as a possible exercise for a student. In order to give it some meaning it must be changed to something like: Two questions arise about the measurement. First, is it "accurate," in other words, did the experiment work properly and were all the necessary factors taken into account? The answer to this depends on the skill of the experimenter in identifying and eliminating all systematic errors. These are discussed in Section 3.4. The second question regards the "precision" of the experiment. In this case the precision of the result is given: the experimenter claims the precision of the result is within 0.03 m/s 1. The person who did the measurement probably had some "gut feeling" for the precision and "hung" an error on the result primarily to communicate this feeling to other people. Common sense should always take precedence over mathematical manipulations. 2. In complicated experiments, error analysis can identify dominant errors and hence provide a guide as to where more effort is needed to improve an experiment. 3. There is virtually no case in the experimental physical sciences where the correct error analysis is to compare the result with a number in some book. A correct experiment is one that is performed correctly, not one that gives a result in agreement with other measurements. 4. The best precision possible for a given experiment is always limited by the apparatus. Polarization measurements in high-energy physics require tens of thousands of person-hours and cost hundreds of thousand of dollars to perform, and a good measurement is within a factor of two. Electrodynamics experiments are considerably cheaper, and often give results to 8 or more significant figures. In both cases, the experimenter must struggle with the equipment to get the most precise and accurate measurement possible. 3.1.2 Different Types of Errors As mentioned above, there are two types of errors associated with an experimental result: the "precision" and the "accuracy". One well-known text explains the difference this way: " " E.M. Pugh and G.H. Winslow, p. 6. The object of a good experiment is to minimize both the errors of precision and the errors of accuracy. Usually, a given experiment has one or the other type of error dominant, and the experimenter devotes the most effort toward reducing that one. For example, in measuring the height of a sample of geraniums to determine an average value, the random variations within the sample of plants are probably going to be much larger than any possible inaccuracy in the ruler being used. Similarly for many experiments in the biological and life sciences, the experimenter worries most about increasing the precision of his/her measurements. Of course, some experiments in the biological and life sciences are dominated by errors of accuracy. On the other hand, in titrating a sample of HCl acid with NaOH base using a phenolphthalein indicator, the major error in the determination of the original concentration of the acid is likely to be one of the following: (1) the accuracy of the markings on the side of the burette; (2) the transition range of the phenolphthalein indicator; or (3) the skill of the experimenter in splitting the last drop of NaOH. Thus, the accuracy of the determination is likely to be much worse than the precision. This is often the case for experiments in chemistry, but certainly not all. Question: Most experiments use theoretical formulas, and usually those formulas are approximations. Is the error of approximation one of precision or of accuracy? 3.1.3 References There is extensive literature on the topics in this chapter. The following lists some well-known introductions. D.C. Baird, (Prentice-Hall, 1962) E.M. Pugh and G.H. Winslow, (Addison-Wesley, 1966) J.R. Taylor, (University Science Books, 1982) In addition, there is a web document written by the author of that is used to teach this topic to first year Physics undergraduates at the University of Toronto. The following Hyperlink points to that document. 3.2 Determining the Precision 3.2.1 The Standard Deviation In the nineteenth century, Gauss' assistants were doing astronomical measurements. However, they were never able to exactly repeat their results. Finally, Gauss got angry and stormed into the lab, claiming he would show these people how to do the measurements once and for all. The only problem was that Gauss wasn't able to repeat his measurements exactly either! After he recovered his composure, Gauss made a histogram of the results of a particular measurement and discovered the famous Gaussian or bell-shaped curve. Many people's first introduction to this shape is the grade distribution for a course. Here is a sample of such a distribution, using the function . We use a standard package to generate a Probability Distribution Function ( ) of such a "Gaussian" or "normal" distribution. The mean is chosen to be 78 and the standard deviation is chosen to be 10; both the mean and standard deviation are defined below. We then normalize the distribution so the maximum value is close to the maximum number in the histogram and plot the result. In this graph, Finally, we look at the histogram and plot together. We can see the functional form of the Gaussian distribution by giving symbolic values. In this formula, the quantity , and . The is sometimes called the . The definition of is as follows. Here is the total number of measurements and is the result of measurement number . The standard deviation is a measure of the width of the peak, meaning that a larger value gives a wider peak. If we look at the area under the curve from graph, we find that this area is 68 percent of the total area. Thus, any result chosen at random has a 68% change of being within one standard deviation of the mean. We can show this by evaluating the integral. For convenience, we choose the mean to be zero. Now, we numericalize this and multiply by 100 to find the percent. The only problem with the above is that the measurement must be repeated an infinite number of times before the standard deviation can be determined. If is less than infinity, one can only estimate measurements, this is the best estimate. The major difference between this estimate and the definition is the . This is reasonable since if = 1 we know we can't determine Here is an example. Suppose we are to determine the diameter of a small cylinder using a micrometer. We repeat the measurement 10 times along various points on the cylinder and get the following results, in centimeters. The number of measurements is the length of the list. The average or mean is now calculated. Then the standard deviation is to be 0.00185173. We repeat the calculation in a functional style. Note that the package, which is standard with , includes functions to calculate all of these quantities and a great deal more. We close with two points: 1. The standard deviation has been associated with the error in each individual measurement. Section 3.3.2 discusses how to find the error in the estimate of the average. 2. This calculation of the standard deviation is only an estimate. In fact, we can find the expected error in the estimate, As discussed in more detail in Section 3.3, this means that the true standard deviation probably lies in the range of values. Viewed in this way, it is clear that the last few digits in the numbers above for function adjusts these significant figures based on the error. is discussed further in Section 3.3.1. 3.2.2 The Reading Error There is another type of error associated with a directly measured quantity, called the "reading error". Referring again to the example of Section 3.2.1, the measurements of the diameter were performed with a micrometer. The particular micrometer used had scale divisions every 0.001 cm. However, it was possible to estimate the reading of the micrometer between the divisions, and this was done in this example. But, there is a reading error associated with this estimation. For example, the first data point is 1.6515 cm. Could it have been 1.6516 cm instead? How about 1.6519 cm? There is no fixed rule to answer the question: the person doing the measurement must guess how well he or she can read the instrument. A reasonable guess of the reading error of this micrometer might be 0.0002 cm on a good day. If the experimenter were up late the night before, the reading error might be 0.0005 cm. An important and sometimes difficult question is whether the reading error of an instrument is "distributed randomly". Random reading errors are caused by the finite precision of the experiment. If an experimenter consistently reads the micrometer 1 cm lower than the actual value, then the reading error is not random. For a digital instrument, the reading error is ± one-half of the last digit. Note that this assumes that the instrument has been properly engineered to round a reading correctly on the display. 3.2.3 "THE" Error So far, we have found two different errors associated with a directly measured quantity: the standard deviation and the reading error. So, which one is the actual real error of precision in the quantity? The answer is both! However, fortunately it almost always turns out that one will be larger than the other, so the smaller of the two can be ignored. In the diameter example being used in this section, the estimate of the standard deviation was found to be 0.00185 cm, while the reading error was only 0.0002 cm. Thus, we can use the standard deviation estimate to characterize the error in each measurement. Another way of saying the same thing is that the observed spread of values in this example is not accounted for by the reading error. If the observed spread were more or less accounted for by the reading error, it would not be necessary to estimate the standard deviation, since the reading error would be the error in each measurement. Of course, everything in this section is related to the precision of the experiment. Discussion of the accuracy of the experiment is in Section 3.4. 3.2.4 Rejection of Measurements Often when repeating measurements one value appears to be spurious and we would like to throw it out. Also, when taking a series of measurements, sometimes one value appears "out of line". Here we discuss some guidelines on rejection of measurements; further information appears in Chapter 7. It is important to emphasize that the whole topic of rejection of measurements is awkward. Some scientists feel that the rejection of data is justified unless there is evidence that the data in question is incorrect. Other scientists attempt to deal with this topic by using quasi-objective rules such as 's . Still others, often incorrectly, throw out any data that appear to be incorrect. In this section, some principles and guidelines are presented; further information may be found in many references. First, we note that it is incorrect to expect each and every measurement to overlap within errors. For example, if the error in a particular quantity is characterized by the standard deviation, we only expect 68% of the measurements from a normally distributed population to be within one standard deviation of the mean. Ninety-five percent of the measurements will be within two standard deviations, 99% within three standard deviations, etc., but we never expect 100% of the measurements to overlap within any finite-sized error for a truly Gaussian distribution. Of course, for most experiments the assumption of a Gaussian distribution is only an approximation. If the error in each measurement is taken to be the reading error, again we only expect most, not all, of the measurements to overlap within errors. In this case the meaning of "most", however, is vague and depends on the optimism/conservatism of the experimenter who assigned the error. Thus, it is always dangerous to throw out a measurement. Maybe we are unlucky enough to make a valid measurement that lies ten standard deviations from the population mean. A valid measurement from the tails of the underlying distribution should not be thrown out. It is even more dangerous to throw out a suspect point indicative of an underlying physical process. Very little science would be known today if the experimenter always threw out measurements that didn't match preconceived expectations! In general, there are two different types of experimental data taken in a laboratory and the question of rejecting measurements is handled in slightly different ways for each. The two types of data are the following: 1. A series of measurements taken with one or more variables changed for each data point. An example is the calibration of a thermocouple, in which the output voltage is measured when the thermocouple is at a number of different temperatures. 2. Repeated measurements of the same physical quantity, with all variables held as constant as experimentally possible. An example is the measurement of the height of a sample of geraniums grown under identical conditions from the same batch of seed stock. For a series of measurements (case 1), when one of the data points is out of line the natural tendency is to throw it out. But, as already mentioned, this means you are assuming the result you are attempting to measure. As a rule of thumb, unless there is a physical explanation of why the suspect value is spurious and it is no more than three standard deviations away from the expected value, it should probably be kept. Chapter 7 deals further with this case. For repeated measurements (case 2), the situation is a little different. Say you are measuring the time for a pendulum to undergo 20 oscillations and you repeat the measurement five times. Assume that four of these trials are within 0.1 seconds of each other, but the fifth trial differs from these by 1.4 seconds ( , more than three standard deviations away from the mean of the "good" values). There is no known reason why that one measurement differs from all the others. Nonetheless, you may be justified in throwing it out. Say that, unknown to you, just as that measurement was being taken, a gravity wave swept through your region of spacetime. However, if you are trying to measure the period of the pendulum when there are no gravity waves affecting the measurement, then throwing out that one result is reasonable. (Although trying to repeat the measurement to find the existence of gravity waves will certainly be more fun!) So whatever the reason for a suspect value, the rule of thumb is that it may be thrown out provided that fact is well documented and that the measurement is repeated a number of times more to convince the experimenter that he/she is not throwing out an important piece of data indicating a new physical process. 3.3 Propagation of Errors of Precision 3.3.1 Discussion and Examples Usually, errors of precision are probabilistic. This means that the experimenter is saying that the actual value of some parameter is within a specified range. For example, if the half-width of the range equals one standard deviation, then the probability is about 68% that over repeated experimentation the true mean will fall within the range; if the half-width of the range is twice the standard deviation, the probability is 95%, etc. If we have two variables, say and , and want to combine them to form a new variable, we want the error in the combination to preserve this probability. The correct procedure to do this is to combine errors in quadrature, which is the square root of the sum of the squares. supplies a function. For simple combinations of data with random errors, the correct procedure can be summarized in three rules. will stand for the errors of precision in , , and , respectively. We assume that and are independent of each other. Note that all three rules assume that the error, say , is small compared to the value of . If z = x * y or then In words, the fractional error in is the quadrature of the fractional errors in and . If z = x + y or z = x - y then In words, the error in is the quadrature of the errors in and . If then or equivalently includes functions to combine data using the above rules. They are named , , , , and . Imagine we have pressure data, measured in centimeters of Hg, and volume data measured in arbitrary units. Each data point consists of { , } pairs. We calculate the pressure times the volume. In the above, the values of and have been multiplied and the errors have ben combined using Rule 1. There is an equivalent form for this calculation. Consider the first of the volume data: {11.28156820762763, 0.031}. The error means that the true value is claimed by the experimenter to probably lie between 11.25 and 11.31. Thus, all the significant figures presented to the right of 11.28 for that data point really aren't significant. The function will adjust the volume data. Notice that by default, uses the two most significant digits in the error for adjusting the values. This can be controlled with the option. For most cases, the default of two digits is reasonable. As discussed in Section 3.2.1, if we assume a normal distribution for the data, then the fractional error in the determination of the standard deviation , and can be written as follows. Thus, using this as a general rule of thumb for all errors of precision, the estimate of the error is only good to 10%, ( one significant figure, unless is greater than 51) . Nonetheless, keeping two significant figures handles cases such as 0.035 vs. 0.030, where some significance may be attached to the final digit. You should be aware that when a datum is massaged by , the extra digits are dropped. By default, and the other functions use the function. The use of is controlled using the option. The number of digits can be adjusted. To form a power, say, we might be tempted to just do function. Finally, imagine that for some reason we wish to form a combination. We might be tempted to solve this with the following. then the error is Here is an example solving . We shall use and below to avoid overwriting the symbols and . First we calculate the total derivative. Next we form the error. Now we can evaluate using the pressure and volume data to get a list of errors. Next we form the list of pairs. The function combines these steps with default significant figure adjustment. The function can be used in place of the other functions discussed above. In this example, the function will be somewhat faster. There is a caveat in using . The expression must contain only symbols, numerical constants, and arithmetic operations. Otherwise, the function will be unable to take the derivatives of the expression necessary to calculate the form of the error. The other functions have no such limitation. 3.3.1.1 Another Approach to Error Propagation: The and Datum value error Data[{{789.7, 2.2}, {790.8, 2.3}, {791.2, 2.3}, {792.6, 2.4}, {791.8, 2.5},
{792.2, 2.5}, {794.7, 2.6}, {794., 2.6}, {794.4, 2.7}, {795.3, 2.8},
{796.4, 2.8}}]Data[{{789.7, 2.2}, {790.8, 2.3}, {791.2, 2.3}, {792.6, 2.4}, {791.8, 2.5},
{792.2, 2.5}, {794.7, 2.6}, {794., 2.6}, {794.4, 2.7}, {795.3, 2.8},
{796.4, 2.8}}] The wrapper can be removed. {{789.7, 2.2}, {790.8, 2.3}, {791.2, 2.3}, {792.6, 2.4}, {791.8, 2.5},
{792.2, 2.5}, {794.7, 2.6}, {794., 2.6}, {794.4, 2.7}, {795.3, 2.8}, {796.4, 2.8}}{{789.7, 2.2}, {790.8, 2.3}, {791.2, 2.3}, {792.6, 2.4}, {791.8, 2.5},
{792.2, 2.5}, {794.7, 2.6}, {794., 2.6}, {794.4, 2.7}, {795.3, 2.8}, {796.4, 2.8}} The reason why the output of the previous two commands has been formatted as is that typesets the pairs using ± for output. A similar construct can be used with individual data points. Datum[{70, 0.04}]Datum[{70, 0.04}] Just as for , the typesetting of uses The and constructs provide "automatic" error propagation for multiplication, division, addition, subtraction, and raising to a power. Another advantage of these constructs is that the rules built into know how to combine data with constants. The rules also know how to propagate errors for many transcendental functions. This rule assumes that the error is small relative to the value, so we can approximate. or arguments, are given by . We have seen that typesets the and constructs using ±. The function can be used directly, and provided its arguments are numeric, errors will be propagated. One may typeset the ± into the input expression, and errors will again be propagated. The ± input mechanism can combine terms by addition, subtraction, multiplication, division, raising to a power, addition and multiplication by a constant number, and use of the . The rules used by for ± are only for numeric arguments. This makes different than 3.3.1.2 Why Quadrature? Here we justify combining errors in quadrature. Although they are not proofs in the usual pristine mathematical sense, they are correct and can be made rigorous if desired. First, you may already know about the "Random Walk" problem in which a player starts at the point = 0 and at each move steps either forward (toward + ) or backward (toward - ). The choice of direction is made randomly for each move by, say, flipping a coin. If each step covers a distance , then after steps the expected most probable distance of the player from the origin can be shown to be Thus, the distance goes up as the square root of the number of steps. Now consider a situation where measurements of a quantity are performed, each with an identical random error . We find the sum of the measurements. , it is equally likely to be + as - , and which is essentially random. Thus, the expected most probable error in the sum goes up as the square root of the number of measurements. This is exactly the result obtained by combining the errors in quadrature. Another similar way of thinking about the errors is that in an abstract linear error space, the errors span the space. If the errors are probabilistic and uncorrelated, the errors in fact are linearly independent (orthogonal) and thus form a basis for the space. Thus, we would expect that to add these independent random errors, we would have to use Pythagoras' theorem, which is just combining them in quadrature. 3.3.2 Finding the Error in an Average The rules for propagation of errors, discussed in Section 3.3.1, allow one to find the error in an average or mean of a number of repeated measurements. Recall that to compute the average, first the sum of all the measurements is found, and the rule for addition of quantities allows the computation of the error in the sum. Next, the sum is divided by the number of measurements, and the rule for division of quantities allows the calculation of the error in the result ( the error of the mean). In the case that the error in each measurement has the same value, the result of applying these rules for propagation of errors can be summarized as a theorem. Theorem: If the measurement of a random variable is repeated times, and the random variable has standard deviation , then the standard deviation in the mean is Proof: One makes measurements, each with error . {x1, errx}, {x2, errx}, ... , {xn, errx} We calculate the sum. sumx = x1 + x2 + ... + xn We calculate the error in the sum. This last line is the key: by repeating the measurements times, the error in the sum only goes up as [ ]. The mean Applying the rule for division we get the following. This completes the proof. The quantity called Here is an example. In Section 3.2.1, 10 measurements of the diameter of a small cylinder were discussed. The mean of the measurements was 1.6514 cm and the standard deviation was 0.00185 cm. Now we can calculate the mean and its error, adjusted for significant figures. Note that presenting this result without significant figure adjustment makes no sense. The above number implies that there is meaning in the one-hundred-millionth part of a centimeter. Here is another example. Imagine you are weighing an object on a "dial balance" in which you turn a dial until the pointer balances, and then read the mass from the marking on the dial. You find = 26.10 ± 0.01 g. The 0.01 g is the reading error of the balance, and is about as good as you can read that particular piece of equipment. You remove the mass from the balance, put it back on, weigh it again, and get = 26.10 ± 0.01 g. You get a friend to try it and she gets the same result. You get another friend to weigh the mass and he also gets = 26.10 ± 0.01 g. So you have four measurements of the mass of the body, each with an identical result. Do you think the theorem applies in this case? If yes, you would quote = 26.100 ± 0.01/ [4] = 26.100 ± 0.005 g. How about if you went out on the street and started bringing strangers in to repeat the measurement, each and every one of whom got = 26.10 ± 0.01 g. So after a few weeks, you have 10,000 identical measurements. Would the error in the mass, as measured on that $50 balance, really be the following? The point is that these rules of statistics are only a rough guide and in a situation like this example where they probably don't apply, don't be afraid to ignore them and use your "uncommon sense". In this example, presenting your result as = 26.10 ± 0.01 g is probably the reasonable thing to do. 3.4 Calibration, Accuracy, and Systematic Errors In Section 3.1.2, we made the distinction between errors of precision and accuracy by imagining that we had performed a timing measurement with a very precise pendulum clock, but had set its length wrong, leading to an inaccurate result. Here we discuss these types of errors of accuracy. To get some insight into how such a wrong length can arise, you may wish to try comparing the scales of two rulers made by different companies — discrepancies of 3 mm across 30 cm are common! If we have access to a ruler we trust ( a "calibration standard"), we can use it to calibrate another ruler. One reasonable way to use the calibration is that if our instrument measures and the standard records , then we can multiply all readings of our instrument by / . Since the correction is usually very small, it will practically never affect the error of precision, which is also small. Calibration standards are, almost by definition, too delicate and/or expensive to use for direct measurement. Here is an example. We are measuring a voltage using an analog Philips multimeter, model PM2400/02. The result is 6.50 V, measured on the 10 V scale, and the reading error is decided on as 0.03 V, which is 0.5%. Repeating the measurement gives identical results. It is calculated by the experimenter that the effect of the voltmeter on the circuit being measured is less than 0.003% and hence negligible. However, the manufacturer of the instrument only claims an accuracy of 3% of full scale (10 V), which here corresponds to 0.3 V. Now, what this claimed accuracy means is that the manufacturer of the instrument claims to control the tolerances of the components inside the box to the point where the value read on the meter will be within 3% times the scale of the actual value. Furthermore, this is not a random error; a given meter will supposedly always read too high or too low when measurements are repeated on the same scale. Thus, repeating measurements will not reduce this error. A further problem with this accuracy is that while most good manufacturers (including Philips) tend to be quite conservative and give trustworthy specifications, there are some manufacturers who have the specifications written by the sales department instead of the engineering department. And even Philips cannot take into account that maybe the last person to use the meter dropped it. Nonetheless, in this case it is probably reasonable to accept the manufacturer's claimed accuracy and take the measured voltage to be 6.5 ± 0.3 V. If you want or need to know the voltage better than that, there are two alternatives: use a better, more expensive voltmeter to take the measurement or calibrate the existing meter. Using a better voltmeter, of course, gives a better result. Say you used a Fluke 8000A digital multimeter and measured the voltage to be 6.63 V. However, you're still in the same position of having to accept the manufacturer's claimed accuracy, in this case (0.1% of reading + 1 digit) = 0.02 V. To do better than this, you must use an even better voltmeter, which again requires accepting the accuracy of this even better instrument and so on, ad infinitum, until you run out of time, patience, or money. Say we decide instead to calibrate the Philips meter using the Fluke meter as the calibration standard. Such a procedure is usually justified only if a large number of measurements were performed with the Philips meter. Why spend half an hour calibrating the Philips meter for just one measurement when you could use the Fluke meter directly? We measure four voltages using both the Philips and the Fluke meter. For the Philips instrument we are not interested in its accuracy, which is why we are calibrating the instrument. So we will use the reading error of the Philips instrument as the error in its measurements and the accuracy of the Fluke instrument as the error in its measurements. We form lists of the results of the measurements. We can examine the differences between the readings either by dividing the Fluke results by the Philips or by subtracting the two values. The second set of numbers is closer to the same value than the first set, so in this case adding a correction to the Philips measurement is perhaps more appropriate than multiplying by a correction. We form a new data set of format { }. We can guess, then, that for a Philips measurement of 6.50 V the appropriate correction factor is 0.11 ± 0.04 V, where the estimated error is a guess based partly on a fear that the meter's inaccuracy may not be as smooth as the four data points indicate. Thus, the corrected Philips reading can be calculated. (You may wish to know that all the numbers in this example are real data and that when the Philips meter read 6.50 V, the Fluke meter measured the voltage to be 6.63 ± 0.02 V.) Finally, a further subtlety: Ohm's law states that the resistance is related to the voltage and the current across the resistor according to the following equation. V = IR Imagine that we are trying to determine an unknown resistance using this law and are using the Philips meter to measure the voltage. Essentially the resistance is the slope of a graph of voltage versus current. If the Philips meter is systematically measuring all voltages too big by, say, 2%, that systematic error of accuracy will have no effect on the slope and therefore will have no effect on the determination of the resistance . So in this case and for this measurement, we may be quite justified in ignoring the inaccuracy of the voltmeter entirely and using the reading error to determine the uncertainty in the determination of . 3.5 Summary of the Error Propagation Routines | - Wolfram|Alpha Notebook Edition
- Mobile Apps
- Wolfram Workbench
- Volume & Site Licensing
- View all...
- For Customers
- Online Store
- Product Registration
- Product Downloads
- Service Plans Benefits
- User Portal
- Your Account
- Customer Service
- Get Started with Wolfram
- Fast Introduction for Math Students
- Public Resources
- Wolfram|Alpha
- Resource System
- Connected Devices Project
- Wolfram Data Drop
- Wolfram Science
- Computational Thinking
- About Wolfram
- Legal & Privacy Policy
Sciencing_Icons_Science SCIENCESciencing_icons_biology biology, sciencing_icons_cells cells, sciencing_icons_molecular molecular, sciencing_icons_microorganisms microorganisms, sciencing_icons_genetics genetics, sciencing_icons_human body human body, sciencing_icons_ecology ecology, sciencing_icons_chemistry chemistry, sciencing_icons_atomic & molecular structure atomic & molecular structure, sciencing_icons_bonds bonds, sciencing_icons_reactions reactions, sciencing_icons_stoichiometry stoichiometry, sciencing_icons_solutions solutions, sciencing_icons_acids & bases acids & bases, sciencing_icons_thermodynamics thermodynamics, sciencing_icons_organic chemistry organic chemistry, sciencing_icons_physics physics, sciencing_icons_fundamentals-physics fundamentals, sciencing_icons_electronics electronics, sciencing_icons_waves waves, sciencing_icons_energy energy, sciencing_icons_fluid fluid, sciencing_icons_astronomy astronomy, sciencing_icons_geology geology, sciencing_icons_fundamentals-geology fundamentals, sciencing_icons_minerals & rocks minerals & rocks, sciencing_icons_earth scructure earth structure, sciencing_icons_fossils fossils, sciencing_icons_natural disasters natural disasters, sciencing_icons_nature nature, sciencing_icons_ecosystems ecosystems, sciencing_icons_environment environment, sciencing_icons_insects insects, sciencing_icons_plants & mushrooms plants & mushrooms, sciencing_icons_animals animals, sciencing_icons_math math, sciencing_icons_arithmetic arithmetic, sciencing_icons_addition & subtraction addition & subtraction, sciencing_icons_multiplication & division multiplication & division, sciencing_icons_decimals decimals, sciencing_icons_fractions fractions, sciencing_icons_conversions conversions, sciencing_icons_algebra algebra, sciencing_icons_working with units working with units, sciencing_icons_equations & expressions equations & expressions, sciencing_icons_ratios & proportions ratios & proportions, sciencing_icons_inequalities inequalities, sciencing_icons_exponents & logarithms exponents & logarithms, sciencing_icons_factorization factorization, sciencing_icons_functions functions, sciencing_icons_linear equations linear equations, sciencing_icons_graphs graphs, sciencing_icons_quadratics quadratics, sciencing_icons_polynomials polynomials, sciencing_icons_geometry geometry, sciencing_icons_fundamentals-geometry fundamentals, sciencing_icons_cartesian cartesian, sciencing_icons_circles circles, sciencing_icons_solids solids, sciencing_icons_trigonometry trigonometry, sciencing_icons_probability-statistics probability & statistics, sciencing_icons_mean-median-mode mean/median/mode, sciencing_icons_independent-dependent variables independent/dependent variables, sciencing_icons_deviation deviation, sciencing_icons_correlation correlation, sciencing_icons_sampling sampling, sciencing_icons_distributions distributions, sciencing_icons_probability probability, sciencing_icons_calculus calculus, sciencing_icons_differentiation-integration differentiation/integration, sciencing_icons_application application, sciencing_icons_projects projects, sciencing_icons_news news. - Share Tweet Email Print
- Home ⋅
- Science Fair Project Ideas for Kids, Middle & High School Students ⋅
Reasons for Error in a Chemistry Experiment Errors in Titration ExperimentsTo a scientist, the definition of "error" is, in some cases, different from the normal use of this term. An error in chemistry still often means a mistake, such as reading a scale incorrectly, but it is also the normal, unavoidable inaccuracies associated with measurements in a lab. Using this expanded definition, there are many different sources of error in an experiment or scientific process. Human ErrorA few errors in chemistry experiments are due simply to mistakes on the part of the person performing the work. There are an endless number of potential mistakes in lab work, but some of the most common include misreading gauges, making math mistakes during dilutions and other types of calculations and spilling chemicals during transfer. Depending on the type of mistake and the stage at which it happens, the associated degree of error in the experimental results will vary widely in magnitude. Improper CalibrationsIncorrect or non-existent calibration of instruments is another common source of error in chemistry. Calibration is the process of adjusting or checking an instrument to ensure that the readings it gives are accurate. To calibrate a weigh scale, for example, you might place an object known to weigh 10 grams on the scale, then check that the scale reads 10 grams. Instruments which are not calibrated or are improperly calibrated are not uncommon in chemical labs and lead to wrong results. Measurement EstimationIn the expanded meaning of "error" in science, the process of estimating a measurement is considered a source of error. For example, a technician filling a beaker with water to a given volume has to watch the water level and stop when it is level with the filling line marked on the container. Unavoidably, even the most careful technician will sometimes be slightly over or below the mark even if only by a very small amount. Similar errors also occur in other circumstances, such as when estimating the end point of a reaction by looking for a specific color change in the reacting chemicals. Measurement Device LimitationsChemists also consider the limitations of measurement equipment in a lab as a source of error. Every instrument or device, no matter how accurate, will have some degree of imprecision associated with it. For example, a measuring flask is provided by the manufacturer with an acknowledged imprecision of from 1 to 5 percent. Using this glassware to make measurements in a lab therefore introduces an error based on that imprecision. In the same manner, other instruments such as weigh scales also have inherent imprecision that unavoidably causes some error. Related ArticlesAcid base titration sources of error improvements, definition of endpoint titration, how to calculate calibration curves, what is a constant error, how to calibrate a graduated cylinder, the disadvantages of analog multimeters, how to convert ng/ml to iu, how to determine the concentration of a titration, how to write a lab report about titration, how to improve your precision in the lab, how to make dilutions, the difference between systematic & random errors, what is the ph level of baking soda, theodolite types, purpose of titration, how to read a western blot, laboratory glassware and functions, how to use a metric scale ruler, how is titration different from colorimetry. - Michigan Technological University: Error Analysis: Physical Chemistry Laboratory
About the Author Michael Judge has been writing for over a decade and has been published in "The Globe and Mail" (Canada's national newspaper) and the U.K. magazine "New Scientist." He holds a Master of Science from the University of Waterloo. Michael has worked for an aerospace firm where he was in charge of rocket propellant formulation and is now a college instructor. Find Your Next Great Science Fair Project! GOHave a language expert improve your writingRun a free plagiarism check in 10 minutes, generate accurate citations for free. Methodology - Random vs. Systematic Error | Definition & Examples
Random vs. Systematic Error | Definition & ExamplesPublished on May 7, 2021 by Pritha Bhandari . Revised on June 22, 2023. In scientific research, measurement error is the difference between an observed value and the true value of something. It’s also called observation error or experimental error. There are two main types of measurement error: Random error is a chance difference between the observed and true values of something (e.g., a researcher misreading a weighing scale records an incorrect measurement). - Systematic error is a consistent or proportional difference between the observed and true values of something (e.g., a miscalibrated scale consistently registers weights as higher than they actually are).
By recognizing the sources of error, you can reduce their impacts and record accurate and precise measurements. Gone unnoticed, these errors can lead to research biases like omitted variable bias or information bias . Table of contentsAre random or systematic errors worse, random error, reducing random error, systematic error, reducing systematic error, other interesting articles, frequently asked questions about random and systematic error. In research, systematic errors are generally a bigger problem than random errors. Random error isn’t necessarily a mistake, but rather a natural part of measurement. There is always some variability in measurements, even when you measure the same thing repeatedly, because of fluctuations in the environment, the instrument, or your own interpretations. But variability can be a problem when it affects your ability to draw valid conclusions about relationships between variables . This is more likely to occur as a result of systematic error. Precision vs accuracyRandom error mainly affects precision , which is how reproducible the same measurement is under equivalent circumstances. In contrast, systematic error affects the accuracy of a measurement, or how close the observed value is to the true value. Taking measurements is similar to hitting a central target on a dartboard. For accurate measurements, you aim to get your dart (your observations) as close to the target (the true values) as you possibly can. For precise measurements, you aim to get repeated observations as close to each other as possible. Random error introduces variability between different measurements of the same thing, while systematic error skews your measurement away from the true value in a specific direction.  When you only have random error, if you measure the same thing multiple times, your measurements will tend to cluster or vary around the true value. Some values will be higher than the true score, while others will be lower. When you average out these measurements, you’ll get very close to the true score. For this reason, random error isn’t considered a big problem when you’re collecting data from a large sample—the errors in different directions will cancel each other out when you calculate descriptive statistics . But it could affect the precision of your dataset when you have a small sample. Systematic errors are much more problematic than random errors because they can skew your data to lead you to false conclusions. If you have systematic error, your measurements will be biased away from the true values. Ultimately, you might make a false positive or a false negative conclusion (a Type I or II error ) about the relationship between the variables you’re studying. Prevent plagiarism. Run a free check.Random error affects your measurements in unpredictable ways: your measurements are equally likely to be higher or lower than the true values. In the graph below, the black line represents a perfect match between the true scores and observed scores of a scale. In an ideal world, all of your data would fall on exactly that line. The green dots represent the actual observed scores for each measurement with random error added.  Random error is referred to as “noise”, because it blurs the true value (or the “signal”) of what’s being measured. Keeping random error low helps you collect precise data. Sources of random errorsSome common sources of random error include: - natural variations in real world or experimental contexts.
- imprecise or unreliable measurement instruments.
- individual differences between participants or units.
- poorly controlled experimental procedures.
| Random error source | Example | | Natural variations in context | In an about memory capacity, your participants are scheduled for memory tests at different times of day. However, some participants tend to perform better in the morning while others perform better later in the day, so your measurements do not reflect the true extent of memory capacity for each individual. | | Imprecise instrument | You measure wrist circumference using a tape measure. But your tape measure is only accurate to the nearest half-centimeter, so you round each measurement up or down when you record data. | | Individual differences | You ask participants to administer a safe electric shock to themselves and rate their pain level on a 7-point rating scale. Because pain is subjective, it’s hard to reliably measure. Some participants overstate their levels of pain, while others understate their levels of pain. | Random error is almost always present in research, even in highly controlled settings. While you can’t eradicate it completely, you can reduce random error using the following methods. Take repeated measurementsA simple way to increase precision is by taking repeated measurements and using their average. For example, you might measure the wrist circumference of a participant three times and get slightly different lengths each time. Taking the mean of the three measurements, instead of using just one, brings you much closer to the true value.  Increase your sample sizeLarge samples have less random error than small samples. That’s because the errors in different directions cancel each other out more efficiently when you have more data points. Collecting data from a large sample increases precision and statistical power . Control variablesIn controlled experiments , you should carefully control any extraneous variables that could impact your measurements. These should be controlled for all participants so that you remove key sources of random error across the board. Systematic error means that your measurements of the same thing will vary in predictable ways: every measurement will differ from the true measurement in the same direction, and even by the same amount in some cases. Systematic error is also referred to as bias because your data is skewed in standardized ways that hide the true values. This may lead to inaccurate conclusions. Types of systematic errorsOffset errors and scale factor errors are two quantifiable types of systematic error. An offset error occurs when a scale isn’t calibrated to a correct zero point. It’s also called an additive error or a zero-setting error. A scale factor error is when measurements consistently differ from the true value proportionally (e.g., by 10%). It’s also referred to as a correlational systematic error or a multiplier error. You can plot offset errors and scale factor errors in graphs to identify their differences. In the graphs below, the black line shows when your observed value is the exact true value, and there is no random error. The blue line is an offset error: it shifts all of your observed values upwards or downwards by a fixed amount (here, it’s one additional unit). The purple line is a scale factor error: all of your observed values are multiplied by a factor—all values are shifted in the same direction by the same proportion, but by different absolute amounts.  Sources of systematic errorsThe sources of systematic error can range from your research materials to your data collection procedures and to your analysis techniques. This isn’t an exhaustive list of systematic error sources, because they can come from all aspects of research. Response bias occurs when your research materials (e.g., questionnaires ) prompt participants to answer or act in inauthentic ways through leading questions . For example, social desirability bias can lead participants try to conform to societal norms, even if that’s not how they truly feel. Your question states: “Experts believe that only systematic actions can reduce the effects of climate change. Do you agree that individual actions are pointless?” Experimenter drift occurs when observers become fatigued, bored, or less motivated after long periods of data collection or coding, and they slowly depart from using standardized procedures in identifiable ways. Initially, you code all subtle and obvious behaviors that fit your criteria as cooperative. But after spending days on this task, you only code extremely obviously helpful actions as cooperative. Sampling bias occurs when some members of a population are more likely to be included in your study than others. It reduces the generalizability of your findings, because your sample isn’t representative of the whole population. Receive feedback on language, structure, and formattingProfessional editors proofread and edit your paper by focusing on: - Academic style
- Vague sentences
- Style consistency
See an example  You can reduce systematic errors by implementing these methods in your study. TriangulationTriangulation means using multiple techniques to record observations so that you’re not relying on only one instrument or method. For example, if you’re measuring stress levels, you can use survey responses, physiological recordings, and reaction times as indicators. You can check whether all three of these measurements converge or overlap to make sure that your results don’t depend on the exact instrument used. Regular calibrationCalibrating an instrument means comparing what the instrument records with the true value of a known, standard quantity. Regularly calibrating your instrument with an accurate reference helps reduce the likelihood of systematic errors affecting your study. You can also calibrate observers or researchers in terms of how they code or record data. Use standard protocols and routine checks to avoid experimenter drift. RandomizationProbability sampling methods help ensure that your sample doesn’t systematically differ from the population. In addition, if you’re doing an experiment, use random assignment to place participants into different treatment conditions. This helps counter bias by balancing participant characteristics across groups. Wherever possible, you should hide the condition assignment from participants and researchers through masking (blinding) . Participants’ behaviors or responses can be influenced by experimenter expectancies and demand characteristics in the environment, so controlling these will help you reduce systematic bias. If you want to know more about statistics , methodology , or research bias , make sure to check out some of our other articles with explanations and examples. - Normal distribution
- Degrees of freedom
- Null hypothesis
- Discourse analysis
- Control groups
- Mixed methods research
- Non-probability sampling
- Quantitative research
- Ecological validity
Research bias - Rosenthal effect
- Implicit bias
- Cognitive bias
- Selection bias
- Negativity bias
- Status quo bias
Random and systematic error are two types of measurement error. Systematic error is a consistent or proportional difference between the observed and true values of something (e.g., a miscalibrated scale consistently records weights as higher than they actually are). Systematic error is generally a bigger problem in research. With random error, multiple measurements will tend to cluster around the true value. When you’re collecting data from a large sample , the errors in different directions will cancel each other out. Systematic errors are much more problematic because they can skew your data away from the true value. This can lead you to false conclusions ( Type I and II errors ) about the relationship between the variables you’re studying. Random error is almost always present in scientific studies, even in highly controlled settings. While you can’t eradicate it completely, you can reduce random error by taking repeated measurements, using a large sample, and controlling extraneous variables . You can avoid systematic error through careful design of your sampling , data collection , and analysis procedures. For example, use triangulation to measure your variables using multiple methods; regularly calibrate instruments or procedures; use random sampling and random assignment ; and apply masking (blinding) where possible. Cite this Scribbr articleIf you want to cite this source, you can copy and paste the citation or click the “Cite this Scribbr article” button to automatically add the citation to our free Citation Generator. Bhandari, P. (2023, June 22). Random vs. Systematic Error | Definition & Examples. Scribbr. Retrieved August 29, 2024, from https://www.scribbr.com/methodology/random-vs-systematic-error/ Is this article helpful? Pritha BhandariOther students also liked, reliability vs. validity in research | difference, types and examples, what is a controlled experiment | definitions & examples, extraneous variables | examples, types & controls, "i thought ai proofreading was useless but..". I've been using Scribbr for years now and I know it's a service that won't disappoint. It does a good job spotting mistakes” - Felixtrument
- Laboratory Equipment
Sources of error in lab experiments and laboratory tests One of the major research aspects of laboratory science is physical and chemical testing; and its test findings are the primary scientific basis for assessing product quality. Physical and chemical laboratory experiments include three primary sources of error : systematic error, random error and human error . These sources of errors in lab should be studied well before any further action. So, what are the particular sources of each error? The reliability of physical and chemical testing has been significantly impaired; by equipment, samples, instruments, lab environment, reagents, operating procedures and other factors; leading to many errors in physical and chemical testing. System Error in laboratory experimentsSystematic error applies to repeated measuring of the same object under repeated conditions of measurement. The amount of the error value is either positive or negative; which is called the fixed system error in laboratory experiments and laboratory tests . Or the error changes show a certain law; which is also called the variable system error, as the measurement conditions varies. The systemic sources of error is caused primarily by: - The incorrect method of measurement in laboratory experiments
- The incorrect method of using the instrument in laboratory experiments
- The failure of the measuring instrument in laboratory experiments
- The performance of the testing tool itself in laboratory experiments
- The inappropriate use of the standard material and the changing environmental conditions in laboratory experiments
With certain steps and proper Laboratory Equipment these sources of errors can be minimized and corrected. Different types of system errors are: Method error in laboratory experimentsThe method error in laboratory experiments refers to the error created by the very process of physical and chemical examination. This error is inevitable so often the test result is low or high. For example, the dissolution of the precipitate is likely to trigger errors while conducting gravimetric analysis in physical and chemical tests; there is no full reaction during the titration , or a side reaction occurs due to the incoherence of the end point of the titration with the metering level. Instrument error in laboratory experimentsThe instrument error in test labs is caused primarily by laboratory instrument inaccuracy . If the meter dial or the zero point is inaccurate, for instance; the measurement result would be too small or too big. Unless the adjustment is not done for too long, the weighing error will eventually occur. The glass gauge has not undergone standard and scale testing; so it is used after purchasing from the manufacturer, which will allow the instrument error to occur. Reagent error in laboratory experimentsThe reagent error in lab test is caused primarily by the impure reagent or the inability to meet the experimental provisions ; such as the existence of impurities in the reagent used in the physical and chemical testing phase; or the existence of contaminated water or reagent contamination that may influence the results of the examination; or the storage or operating climate. Changes in reagents and the like can cause errors in reactants.  Random Error in laboratory experimentsError caused by various unknown factors is known as random error. This error poses erratic changes at random, primarily due to a variety of small, independent, and accidental factors. The random error is atypical from the surface. Since it is accidental, the random error is often called unmeasurable error or accidental error . Statistical analysis can also measure random sources of error in lab, unlike systemic errors; and it can also determine the effect of random errors on the quantity or physical law under investigation. To solve random errors, scientists employ replication. Replication repeats several times a measurement, and takes the average. Although, it should be noted that in the usual physical and chemical testing phase, which has some inevitability, both the systematic error and the random error do exist. The disparity in results caused by the inspection process mistake of the usual physical and chemical inspection personnel, incorrect addition of reagents, inaccurate procedure or reading, mistake in measurement, etc., should be considered “error” and not an error. Thus, if there is a significant difference between repeated measurements of the same measuring object; whether it is caused by “ error ” should be considered. in such situation, the source of error in lab should be examined carefully, and its characteristics should be calculated. An Example of some random sources of errors in labExample for distinguishing between systemic and random errors is; assuming you are using a stop watch to calculate the time needed for ten pendulum oscillations. One cause of error in starting and stopping the watch is your reaction time. You may start soon and stop late during one measurement; you can reverse those errors on the next. These are accidental errors , since all cases are equally probable. Repeated tests yield a sequence of times, all slightly different. In random they differ around an average value. For example, if there is also a systemic mistake, your stop watch doesn’t start from zero; so the calculations will differ, not about the average value, but about the displaced value. In this example both random and systemic source of errors in lab explained. Human Error in laboratory experimentsThe human error in laboratory experiments and lab tests primarily refers to the mistake in physical and chemical inspection phase caused by the factors of the inspector ; particularly in the following three aspects: Operational error in laboratory experimentsOperational error applies to the subjective factors in regular activity of the physical and chemical inspectors. For instance, the sensitivity of the inspector to observing the color would result in errors; or there is no effective protection when weighing the sample, so that the sample is hygroscopic. When washing the precipitate, there is an error in the absence of appropriate washing or extreme washing; Throughout the burning precipitation, did not regulate temperature; Unless the burette is not rinsed in the physical and chemical testing process before the liquid leakage, the liquid hanging phenomenon will occur which will allow the air bubbles to linger at the bottom of the burette after the liquid is injected; Inspectors looking up (or down) the scale at the time of the degree would cause errors. Subjective error in laboratory experimentsSubjective errors are caused mainly by the subjective considerations of physical and chemical test analysts. For example, because of the difference in the degree of sharpness of color perception, some analysts believe the color is dark when the color of the titration end point is discriminated against, but some analysts think the color is brighter; Because the angles from which the scale values are read are different, some analysts feel high while some analysts feel low in situations. Moreover, many observers would have a “pre-entry” tendency in the actual physical and chemical inspection job, that is, subjectively unconsciously biased towards the first measurement value whenever reading the second measurement value. Negligible error in laboratory experimentsNegligible error refers to the mistake caused during the physical and chemical examination by the inspector’s reading mistake, operation error, measurement error etc. A individual can, for example, record an incorrect value, misread a scale, forget a digit while reading a scale, or record a calculation, or make a similar blunder. Errors can lead to incorrect results , and knowing the sources of error in lab will help us mitigate error occurrence and increase test results quality. Leave a Reply Cancel replyYou must be logged in to post a comment. There are no comments yet.  - Science Notes Posts
- Contact Science Notes
- Todd Helmenstine Biography
- Anne Helmenstine Biography
- Free Printable Periodic Tables (PDF and PNG)
- Periodic Table Wallpapers
- Interactive Periodic Table
- Periodic Table Posters
- Science Experiments for Kids
- How to Grow Crystals
- Chemistry Projects
- Fire and Flames Projects
- Holiday Science
- Chemistry Problems With Answers
- Physics Problems
- Unit Conversion Example Problems
- Chemistry Worksheets
- Biology Worksheets
- Periodic Table Worksheets
- Physical Science Worksheets
- Science Lab Worksheets
- My Amazon Books
Calculate Percent Error 5 Percent Error DefinitionPercent error, sometimes referred to as percentage error, is an expression of the difference between a measured value and the known or accepted value . It is often used in science to report the difference between experimental values and expected values.  The formula for calculating percent error is: Note: occasionally, it is useful to know if the error is positive or negative. If you need to know the positive or negative error, this is done by dropping the absolute value brackets in the formula. In most cases, absolute error is fine. For example, in experiments involving yields in chemical reactions, it is unlikely you will obtain more product than theoretically possible. Steps to Calculate the Percent Error- Subtract the accepted value from the experimental value.
- Take the absolute value of step 1
- Divide that answer by the accepted value.
- Multiply that answer by 100 and add the % symbol to express the answer as a percentage .
Example CalculationNow let’s try an example problem. You are given a cube of pure copper. You measure the sides of the cube to find the volume and weigh it to find its mass. When you calculate the density using your measurements, you get 8.78 grams/cm 3 . Copper’s accepted density is 8.96 g/cm 3 . What is your percent error? Solution: experimental value = 8.78 g/cm 3 accepted value = 8.96 g/cm 3 Step 1: Subtract the accepted value from the experimental value. 8.78 g/cm 3 – 8.96 g/cm 3 = -0.18 g/cm 3 Step 2: Take the absolute value of step 1 |-0.18 g/cm 3 | = 0.18 g/cm 3  Step 3: Divide that answer by the accepted value. Step 4: Multiply that answer by 100 and add the % symbol to express the answer as a percentage. 0.02 x 100 = 2 2% The percent error of your density calculation is 2%. Related Posts5 thoughts on “ calculate percent error ”. Percent error is always represented as a positive value. The difference between the actual and experimental value is always the absolute value of the difference. |Experimental-Actual|/Actualx100 so it doesn’t matter how you subtract. The result of the difference is positive and therefore the percent error is positive. Percent error is always positive, but step one still contains the error initially flagged by Mark. The answer in that step should be negative: experimental-accepted=error 8.78 – 8.96 = -0.18 In the article, the answer was edited to be correct (negative), but the values on the left are still not in the right order and don’t yield a negative answer as presented. Mark is not correct. Percent error is always positive regardless of the values of the experimental and actual values. Please see my post to him. Say if you wanted to find acceleration caused by gravity, the accepted value would be the acceleration caused by gravity on earth (9.81…), and the experimental value would be what you calculated gravity as :) If you don’t have an accepted value, the way you express error depends on how you are making the measurement. If it’s a calculated value, like, based on a known about of carbon dioxide dissolved in water, then you have a theoretical value to use instead of the accepted value. If you are performing a chemical reaction to quantify the amount of carbonic acid, the accepted value is the theoretical value if the reaction goes to completion. If you are measuring the value using an instrument, you have uncertainty of the instrument (e.g., a pH meter that measures to the nearest 0.1 units). But, if you are taking measurements, most of the time, measure the concentration more than once, take the average value of your measurements, and use the average (mean) as your accepted value. Error gets complicated, since it also depends on instrument calibration and other factors. Comments are closed. Thank you for visiting nature.com. You are using a browser version with limited support for CSS. To obtain the best experience, we recommend you use a more up to date browser (or turn off compatibility mode in Internet Explorer). In the meantime, to ensure continued support, we are displaying the site without styles and JavaScript. - View all journals
- Explore content
- About the journal
- Publish with us
- Sign up for alerts
- News & Views
- Published: 26 August 2022
MACHINE LEARNING The chemistry of errors- Jacqueline M. Cole ORCID: orcid.org/0000-0002-1552-8743 1 , 2
Nature Chemistry volume 14 , pages 973–975 ( 2022 ) Cite this article 4503 Accesses 6 Citations 17 Altmetric Metrics details - Cheminformatics
- Communicating chemistry
- Computational chemistry
- Synthetic chemistry methodology
The application of machine learning to big data, to make quantitative predictions about reaction outcomes, has been fraught with failure. This is because so many chemical-reaction data are not fit for purpose, but predictions would be less error-prone if synthetic chemists changed their reaction design and reporting practices. This is a preview of subscription content, access via your institution Relevant articlesOpen Access articles citing this article. Rapid planning and analysis of high-throughput experiment arrays for reaction discovery- Babak Mahjour
- , Rui Zhang
- … Tim Cernak
Nature Communications Open Access 03 July 2023 Access optionsAccess Nature and 54 other Nature Portfolio journals Get Nature+, our best-value online-access subscription 24,99 € / 30 days cancel any time Subscribe to this journal Receive 12 print issues and online access 251,40 € per year only 20,95 € per issue Buy this article - Purchase on SpringerLink
- Instant access to full article PDF
Prices may be subject to local taxes which are calculated during checkout 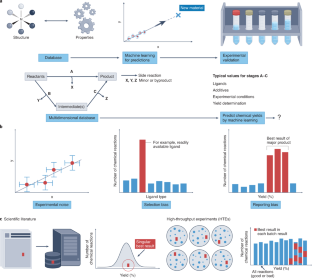 Baptista de Castro, P. et al. NPG Asia Mater. 12 , 35 (2020). Article Google Scholar Gómez-Bombarelli, R. et al. Nat. Mater. 15 , 1120–1127 (2016). Strieth-Kalthoff, F. et al. Angew. Chem. Int. Ed. 61 , e202204647 (2022). Article CAS Google Scholar Perera, D. et al. Science 359 , 429–434 (2018). Ahneman, D. T., Estrada, J. G., Lin, S., Dreher, S. D. & Doyle, A. G. Science 360 , 186–190 (2018). Li, Z. et al. Chem. Mater. 32 , 5650–5663 (2020). Burger, B. et al. Nature 583 , 237–241 (2020). MacLeod, B. P. et al. Science Adv. 6 , eaaz8867 (2020). Download references Author informationAuthors and affiliations. Cavendish Laboratory, University of Cambridge, Cambridge, UK Jacqueline M. Cole ISIS Neutron and Muon Source, STFC Rutherford Appleton Laboratory, Didcot, UK You can also search for this author in PubMed Google Scholar Corresponding authorCorrespondence to Jacqueline M. Cole . Ethics declarationsCompeting interests. The author declares no competing interests. Rights and permissionsReprints and permissions About this articleCite this article. Cole, J.M. The chemistry of errors. Nat. Chem. 14 , 973–975 (2022). https://doi.org/10.1038/s41557-022-01028-6 Download citation Published : 26 August 2022 Issue Date : September 2022 DOI : https://doi.org/10.1038/s41557-022-01028-6 Share this articleAnyone you share the following link with will be able to read this content: Sorry, a shareable link is not currently available for this article. Provided by the Springer Nature SharedIt content-sharing initiative This article is cited byNature Communications (2023) Quick links- Explore articles by subject
- Guide to authors
- Editorial policies
Sign up for the Nature Briefing newsletter — what matters in science, free to your inbox daily.  |


IMAGES
VIDEO
COMMENTS
Here are some more examples of experimental errors. Recall, systematic errors result in all measurements being off the same amount due to old equipment, improper calibration, or mistakes in ...
Examples of Systematic Errors If you forget to calibrate a balance or you're off a bit in the calibration, all mass measurements will be high/low by the same amount. Some instruments require periodic calibration throughout the course of an experiment , so it's good to make a note in your lab notebook to see whether the calibrations appears ...
Dr. Helmenstine holds a Ph.D. in biomedical sciences and is a science writer, educator, and consultant. She has taught science courses at the high school, college, and graduate levels.
Experimental errors in chemistry can be broadly categorized into two types: systematic errors and random errors. Systematic errors are caused by flaws in the experimental setup or procedures and can lead to consistently biased results. Random errors, on the other hand, are caused by chance and can occur unpredictably, leading to fluctuations in ...
These errors are often classified into three main categories: systematic errors, random errors, and human errors. Here are some common types of experimental errors: 1. Systematic Errors. Systematic errors are consistent and predictable errors that occur throughout an experiment. They can arise from flaws in equipment, calibration issues, or ...
Experimental errors can be generally classified as one of two types: • Random (indeterminate): These errors occur with a random magnitude and sign each time the experiment is executed.
When weighing yourself on a scale, you position yourself slightly differently each time. When taking a volume reading in a flask, you may read the value from a different angle each time.; Measuring the mass of a sample on an analytical balance may produce different values as air currents affect the balance or as water enters and leaves the specimen. ...
For example, an uncalibrated scale might always read the mass of an object as 0.5g too high. Because systematic errors are consistent, you can often fix them. There are four types of systematic error: observational, instrumental, environmental, and theoretical. Observational errors occur when you make an incorrect observation. For example, you ...
This chapter is largely a tutorial on handling experimental errors of measurement. Much of the material has been extensively tested with science undergraduates at a variety of levels at the University of Toronto. ... This is often the case for experiments in chemistry, but certainly not all. Question: Most experiments use theoretical formulas ...
Learn how to identify potential sources of experimental error, and see examples that walk through sample problems step-by-step for you to improve your chemistry knowledge and skills.
Here are examples of systematic error: Reading a meniscus above or below eye level always gives an inaccurate reading. The reading is consistently high or low, depending on the viewing angle.
A few errors in chemistry experiments are due simply to mistakes on the part of the person performing the work. There are an endless number of potential mistakes in lab work, but some of the most common include misreading gauges, making math mistakes during dilutions and other types of calculations and spilling chemicals during transfer.
Random and systematic errors are types of measurement error, a difference between the observed and true values of something.
One of the major research aspects of laboratory science is physical and chemical testing, and its test findings are the primary scientific basis for assessing product quality.
Percent error, sometimes referred to as percentage error, is an expression of the difference between a measured value and the known or accepted value. It is often used in science to report the difference between experimental values and expected values.
Beyond calibration and reporting, the best test of reproducibility is to perform intercomparisons between laboratories, either by comparing results to identical experiments reported in the ...
For example, ... ML-based quantitative predictions about chemical reactions require more categories of experimental data ... The chemistry of errors. Nat. Chem. 14, 973-975 (2022). https: ...